




ຊິບ IC ວົງຈອນປະສົມປະສານຫນຶ່ງຈຸດຊື້ EPM240T100C5N IC CPLD 192MC 4.7NS 100TQFP


ຄຸນລັກສະນະຂອງຜະລິດຕະພັນ
| ປະເພດ | ລາຍລະອຽດ |
| ປະເພດ | ວົງຈອນລວມ (ICs) ຝັງ CPLDs (Complex Programmable Logic Devices) |
| Mfr | Intel |
| ຊຸດ | MAX® II |
| ຊຸດ | ຖາດ |
| ຊຸດມາດຕະຖານ | 90 |
| ສະຖານະພາບຜະລິດຕະພັນ | ເຄື່ອນໄຫວ |
| ປະເພດໂປຣແກຣມ | ໃນ System Programmable |
| ເວລາຊັກຊ້າ tpd(1) ສູງສຸດ | 4.7 ນ |
| ການສະຫນອງແຮງດັນ - ພາຍໃນ | 2.5V, 3.3V |
| ຈຳນວນຂອງອົງປະກອບ/ບລັອກ | 240 |
| ຈໍານວນ Macrocells | 192 |
| ຈໍານວນ I/O | 80 |
| ອຸນຫະພູມປະຕິບັດການ | 0°C ~ 85°C (TJ) |
| ປະເພດການຕິດຕັ້ງ | Surface Mount |
| ການຫຸ້ມຫໍ່ / ກໍລະນີ | 100-TQFP |
| ຊຸດອຸປະກອນຜູ້ສະໜອງ | 100-TQFP (14×14) |
| ໝາຍເລກຜະລິດຕະພັນພື້ນຖານ | EPM240 |
ຄ່າໃຊ້ຈ່າຍແມ່ນເປັນຫນຶ່ງໃນບັນຫາໃຫຍ່ທີ່ກໍາລັງປະເຊີນກັບຊິບຫຸ້ມຫໍ່ 3D, ແລະ Foveros ຈະເປັນຄັ້ງທໍາອິດທີ່ Intel ໄດ້ຜະລິດພວກມັນໃນປະລິມານສູງຍ້ອນເຕັກໂນໂລຢີການຫຸ້ມຫໍ່ຊັ້ນນໍາ.Intel, ແນວໃດກໍ່ຕາມ, ເວົ້າວ່າຊິບທີ່ຜະລິດຢູ່ໃນແພັກເກັດ 3D Foveros ແມ່ນລາຄາທີ່ແຂ່ງຂັນກັບການອອກແບບຊິບມາດຕະຖານ - ແລະໃນບາງກໍລະນີອາດຈະຖືກກວ່າ.
Intel ໄດ້ອອກແບບຊິບ Foveros ໃຫ້ມີລາຄາຖືກທີ່ສຸດເທົ່າທີ່ຈະເປັນໄປໄດ້ ແລະຍັງຕອບສະໜອງໄດ້ຕາມເປົ້າໝາຍດ້ານປະສິດທິພາບຂອງບໍລິສັດ - ມັນເປັນຊິບທີ່ມີລາຄາຖືກທີ່ສຸດໃນຊຸດ Meteor Lake.Intel ຍັງບໍ່ທັນໄດ້ແບ່ງປັນຄວາມໄວຂອງ Foveros interconnect / base tile ແຕ່ໄດ້ກ່າວວ່າອົງປະກອບສາມາດແລ່ນໄດ້ບໍ່ເທົ່າໃດ GHz' ໃນການຕັ້ງຄ່າຕົວຕັ້ງຕົວຕີ (ຄໍາຖະແຫຼງທີ່ຊີ້ໃຫ້ເຫັນເຖິງການມີຢູ່ຂອງຊັ້ນກາງຂອງ Intel ກໍາລັງພັດທະນາແລ້ວ. ).ດັ່ງນັ້ນ, Foveros ບໍ່ໄດ້ຮຽກຮ້ອງໃຫ້ຜູ້ອອກແບບປະນີປະນອມກັບຂໍ້ຈໍາກັດຂອງແບນວິດຫຼື latency.
Intel ຍັງຄາດຫວັງວ່າການອອກແບບຈະຂະຫນາດໄດ້ດີໃນດ້ານການປະຕິບັດແລະຄ່າໃຊ້ຈ່າຍ, ຊຶ່ງຫມາຍຄວາມວ່າມັນສາມາດສະເຫນີການອອກແບບພິເສດສໍາລັບພາກສ່ວນຕະຫຼາດອື່ນໆ, ຫຼືຕົວແປຂອງຮຸ່ນທີ່ມີປະສິດທິພາບສູງ.
ຄ່າໃຊ້ຈ່າຍຂອງ nodes ກ້າວຫນ້າທາງດ້ານ transistor ກໍາລັງເຕີບໂຕຢ່າງໃຫຍ່ຫຼວງຍ້ອນວ່າຂະບວນການຊິບຊິລິໂຄນເຂົ້າຫາຂອບເຂດຈໍາກັດຂອງພວກເຂົາ.ແລະການອອກແບບໂມດູນ IP ໃຫມ່ (ເຊັ່ນ: I/O interfaces) ສໍາລັບ nodes ຂະຫນາດນ້ອຍບໍ່ໄດ້ໃຫ້ຜົນຕອບແທນຫຼາຍຂອງການລົງທຶນ.ດັ່ງນັ້ນ, ການໃຊ້ກະເບື້ອງ/chiplets ທີ່ບໍ່ສໍາຄັນຄືນໃຫມ່ໃນ 'ດີພຽງພໍ' nodes ທີ່ມີຢູ່ແລ້ວສາມາດປະຫຍັດເວລາ, ຄ່າໃຊ້ຈ່າຍ, ແລະຊັບພະຍາກອນການພັດທະນາ, ບໍ່ໄດ້ກ່າວເຖິງເຮັດໃຫ້ຂະບວນການທົດສອບງ່າຍຂຶ້ນ.
ສໍາລັບຊິບດຽວ, Intel ຕ້ອງທົດສອບອົງປະກອບຊິບທີ່ແຕກຕ່າງກັນ, ເຊັ່ນ: ຫນ່ວຍຄວາມຈໍາຫຼື PCIe interfaces, ຕິດຕໍ່ກັນ, ເຊິ່ງສາມາດເປັນຂະບວນການທີ່ໃຊ້ເວລາຫຼາຍ.ໃນທາງກົງກັນຂ້າມ, ຜູ້ຜະລິດຊິບຍັງສາມາດທົດສອບຊິບຂະຫນາດນ້ອຍພ້ອມກັນເພື່ອປະຫຍັດເວລາ.ການປົກຫຸ້ມຂອງຍັງມີປະໂຫຍດໃນການອອກແບບຊິບສໍາລັບຊ່ວງ TDP ສະເພາະ, ຍ້ອນວ່າຜູ້ອອກແບບສາມາດປັບແຕ່ງຊິບຂະຫນາດນ້ອຍທີ່ແຕກຕ່າງກັນເພື່ອໃຫ້ເຫມາະສົມກັບຄວາມຕ້ອງການຂອງການອອກແບບ.
ຈຸດເຫຼົ່ານີ້ສ່ວນໃຫຍ່ເປັນສຽງທີ່ຄຸ້ນເຄີຍ, ແລະພວກມັນທັງຫມົດແມ່ນປັດໃຈດຽວກັນທີ່ເຮັດໃຫ້ AMD ລົງໄປສູ່ເສັ້ນທາງຊິບເຊັດໃນປີ 2017. AMD ບໍ່ແມ່ນຄົນທໍາອິດທີ່ໃຊ້ການອອກແບບທີ່ອີງໃສ່ຊິບເຊັດ, ແຕ່ມັນເປັນຜູ້ຜະລິດໃຫຍ່ທໍາອິດທີ່ໃຊ້ປັດຊະຍາການອອກແບບນີ້. ການຜະລິດຊິບທີ່ທັນສະໄຫມຈໍານວນຫຼາຍ, ບາງສິ່ງບາງຢ່າງ Intel ເບິ່ງຄືວ່າໄດ້ມາຊ້າເລັກນ້ອຍ.ແນວໃດກໍ່ຕາມ, ເທັກໂນໂລຍີການຫຸ້ມຫໍ່ 3D ທີ່ສະເໜີມາຂອງ Intel ແມ່ນມີຄວາມຊັບຊ້ອນຫຼາຍກ່ວາການອອກແບບຊັ້ນກາງທາງອິນຊີຂອງ AMD, ເຊິ່ງມີທັງຂໍ້ດີ ແລະ ຂໍ້ເສຍ.
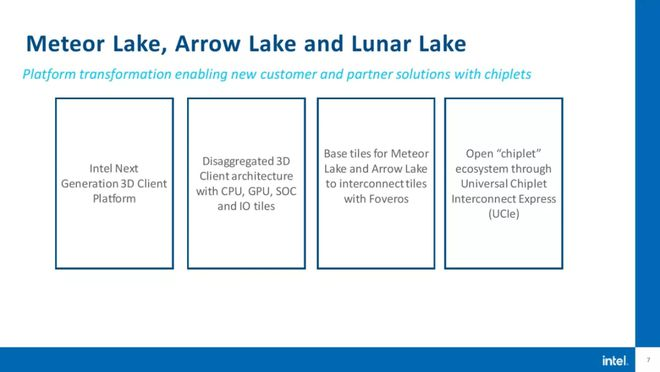
ຄວາມແຕກຕ່າງໃນທີ່ສຸດຈະສະທ້ອນໃຫ້ເຫັນຢູ່ໃນຊິບສໍາເລັດຮູບ, ໂດຍ Intel ກ່າວວ່າຊິບ 3D stacked Meteor Lake ຄາດວ່າຈະມີຢູ່ໃນ 2023, ມີ Arrow Lake ແລະ Lunar Lake ໃນປີ 2024.
Intel ຍັງກ່າວອີກວ່າ ຊິບຊຸບເປີຄອມພີວເຕີ Ponte Vecchio ທີ່ຈະມີ transistor ຫຼາຍກວ່າ 100 ຕື້ໂຕ ຄາດວ່າຈະເປັນຈຸດໃຈກາງຂອງ Aurora ເຊິ່ງເປັນຊຸບເປີຄອມພິວເຕີທີ່ໄວທີ່ສຸດໃນໂລກ.





